
Databus vs. database – knowledge for IIoT developers
The Industrial Internet of Things (IIoT) is full of confusing terms. That’s unavoidable; despite its reuse of familiar concepts in computing and systems, the IIoT is a fundamental change in the way things work. Fundamental changes require fundamentally new concepts. One of the most important is the concept of a 'databus'. Author: Stan Schneider, CEO, Real-Time Innovations (RTI)
The soon-to-be-released IIC reference architecture version 2 contains a pattern called the 'layered databus' pattern. I can’t say much more now about the IIC release, but going through the documentation process has been great for driving crisp definitions. A databus is a data-centric information-sharing technology that implements a virtual, global data space. Software applications read and update entries in a global data space. Updates are shared between applications via a publish-subscribe communications mechanism. Key characteristics of a databus are: the participants/applications directly interface with the data, the infrastructure understands, and can therefore selectively filter the data, and the infrastructure imposes rules and guarantees of Quality of Service (QoS) parameters such as rate, reliability, and security of data flow. Both databases and databuses are, after all, data science concepts. Real-Time Innovations answers the four most common questions.
How is a databus different from a database (of any kind)?
A database implements data-centric storage. It saves old information that you can later search by relating properties of the stored data. A databus implements data-centric interaction. It manages future information by letting you filter by properties of the incoming data. Data centricity can be defined by these properties: The interface is the data. There are no artificial wrappers or blockers to that interface like messages, or objects, or files, or access patterns. The infrastructure understands that data. This enables filtering/searching, tools and selectivity. It decouples applications from the data and thereby removes much of the complexity from the applications. The system manages the data and imposes rules on how applications exchange data. This provides a notion of 'truth'. It enables data lifetimes, data model matching and CRUD interfaces.
A relational database is a data-centric storage technology. Before databases, storage systems were files with application-defined (ad hoc) structure. A database is also a file, but it’s a very special file. A database knows how to interpret the data and enforces access control. A database thus defines 'truth' for the system; data in the database can’t be corrupted or lost.
By enforcing simple rules that control the data model, databases ensure consistency. By exposing the data to search and retrieval by all users, databases greatly ease system integration. By allowing discovery of data and schema, databases also enable generic tools for monitoring, measuring, and mining information.
Like a database, data-centric middleware (a databus) understands the content of the transmitted data. The databus also sends messages, but it sends very special messages. It sends only messages specifically needed to maintain state. Clear rules govern access to the data, how data in the system changes, and when participants get updates. Importantly, only the infrastructure sends messages. To the applications, the system looks like a controlled global data space. Applications interact directly with data and data 'Quality of Service' (QoS) properties like age and rate. There is no application-level awareness or concept of 'message'. Programmes using a databus read and write data, they do not send and receive messages.
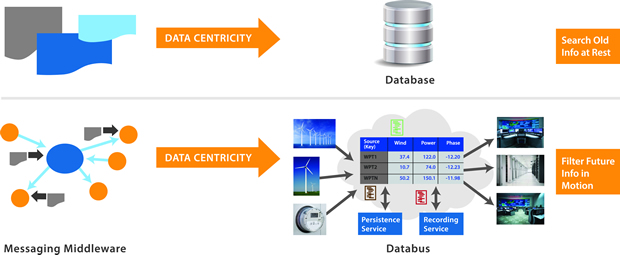
With knowledge of the structure and demands on data, the databus infrastructure can do things like filter information, selecting when or even if to do updates. The infrastructure itself can control QoS like update rate, reliability, and guaranteed notification of peer liveliness. The infrastructure can discover data flows and offer those to applications and generic tools alike. This knowledge of data status, in a distributed system, is a crisp definition of 'truth'. As in databases, the infrastructure exposes the data, both structure and content, to other applications. This accessible source of truth greatly eases system integration. It also enables generic tools and services that monitor and view information flow, route messages, and manage caching.
The participants/applications directly interface with the data – what does that mean?
With 'message-centric' middleware, you write an application that sends data, wrapped in messages, to another application. You may do that by having clients send data to servers, for instance. Both ends need to know something about the other end, usually including things like the schema, but also likely assumed properties of the data. All of them are completely hidden in the application code, making reuse, system integration, and interoperability really hard.
With a databus, you don’t need to know anything about the source applications. You make clear your data needs, and then the databus delivers it. Thus, with a databus, each application interacts only with the data space. As an application, you simply write to the data space or read from the data space with a CRUD interface. Of course, you may require some QoS from that data space, e.g. you need your data updated 100x per second. The data space itself (the databus) will guarantee you get that data (or flag an error). You don’t need to know if there are only one or 27 redundant sources of that data, or if it comes over a network or shared memory, or if it’s a C program on Linux or a C# program on Windows. All interactions are with your own view of the data space. It also makes sense, for instance, to write data to a space with no recipients. In this case, the databus may do absolutely nothing, or it may cache information for later delivery, depending on your QoS settings.
Note that both database and databus technologies replace the application-application interaction with application-data-application interaction. This abstraction is absolutely critical. It decouples applications and greatly eases scaling, interoperability, and system integration. The difference is really one of old data stored in a (likely centralised) database, vs. future data sent directly to the applications from a distributed data space.
How does a databus differ from a CEP engine?
A databus is a fundamentally distributed concept that selects and delivers data from local producers that match a simple specification. A CEP engine is a centralised executable service that is capable of much more complex specifications, but must have all streams of data sent to one place.
A Complex Event Processing (CEP) engine examines an incoming stream of data, looking for patterns you program it to identify. When it finds one of those patterns, you can program it to take action. The patterns can be complex combinations of past and incoming future data. However, it is a single service, running on a single CPU somewhere. It transmits no information.
A databus also looks for patterns of data. However, the specifications are simpler; it makes decisions about each data item as it’s produced. The actions are also simpler; the only action it may take is to send that data to a requestor. The power of a databus is that it is fundamentally distributed. The looking happens locally on potentially hundreds, thousands, or even millions of nodes. Thus, the databus is a very powerful way to select the right data from the right sources and send them to the right places. A databus is sort of like a distributed set of CEP engines, one for every possible source of information, that are automatically programmed by the users of that information. Of course, the databus has many other properties beyond pattern matching, such as schema mediation, redundancy management, transport support, an interoperable protocol, etc.
What application drove the DDS standard and databuses?
The early applications were in intelligent robots, 'information superiority', and large coordinated systems like navy combat management. These systems needed reliability even when components fail, data fast enough to control physical processes, and selective discovery and delivery to scale. Data centricity really simplified application code and controlled interfaces, letting teams of programmers work on large software systems over time. The DDS standard is an active, growing family of standards that was originally driven by both vendors and customers. It has significant use across many verticals, including medical, transportation, smart cities, and energy.
Product Spotlight
APV1111GVY
Panasonic

Panasonic PhotoMOS® Photovoltaic MOSFET High-Power Drivers
| SKU: | |
|---|---|
| Stock: | 3490 |
| Cost: | $3.95 |
